邓侃:谷歌Talk to books引爆搜索方式革命

新智元专栏
作者:邓侃
昨天,新智元介绍了谷歌的全新搜索工具“Talk to Books”,基于自然语言文本理解,用户能够凭语义而非关键词来实现搜索功能。谷歌搜索的“AI化”令人眼前一亮,谷歌是否即将从当今的搜索引擎,革命性地进化到了回答引擎?本文作者,大数医达创始人、CMU 博士邓侃对谷歌的这个新搜索工具的技术原理进行了解读。

今天读到一则新闻,“谷歌发大招:搜索全面AI化,不用关键词就能轻松撩书”。
介绍产品 Talk to Books 时,作者放了一张产品截图。
当用户提问 “What is fun about computer programming?” Talk to Books 自动回答,
“... has been beneficial on many levels. First, computer programming provides a palette with a virtually unlimited potential for creative expression; the thrill of bringing a useful porgram to life rivals the thrill of hearning a new composition being performed for the fist time. Second, a knowledge of computer ...”
from Arduino for Musicians: A complete Guide to Arduino and Teensy Microcontrollers by Brent Edstrom.
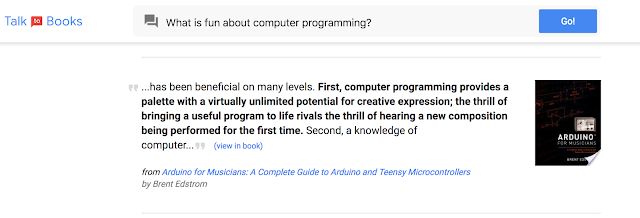
这个例子很震撼,几个原因:
1. 从搜索到回答:
谷歌当今的搜索结果,只是给出文章的链接。而 Talk to Books 的搜索结果,虽然是书的摘要,但是摘要摘得如此精当,几乎是问题的回答。这篇博文是不是在暗示,
谷歌即将从当今的搜索引擎,革命性地进化到了回答引擎?
2. 语义理解:
长期担任过谷歌搜索业务主管,Amit Singhal,在其任内,曾经亲自领衔主持谷歌知识图谱的实现。在介绍知识图谱的价值时,Amit Singhal 说,
谷歌将不再搜索关键词表面上的字符串 “string”,而将直接搜索关键词的内涵语义 “thing”。
在 Talk to Books 的这个例子中,提问中包含 “fun”,而答案中与之呼应的词,包括 “beneficial”、“palette”、“thrill” 等等。注意,是呼应,是相关词,但不是同义词近义词。
如何迅速找到同义词、近义词、相关词?不难猜测,一定与
词向量
有关。如果仅仅用词向量,取代文字表述的词汇,那么基于词向量的搜索引擎,最多是模糊匹配的搜索引擎,但是并非是截图暗示的那种回答引擎。
3. 文章张量树:
论文 [4] 的具体做法是,先把每一篇文章中的每一个词汇,翻译成词汇张量。然后从每一个语句的一连串词汇张量中,提炼出语句张量。再然后把每一个段落的一连串语句张量中,提炼出段落张量。最后从段落张量中,提炼出整个文章的文章张量。
这样,
每篇文章,就构成一个树状的张量集合。
根节点是整个文章的中心思想的文章张量,上层中间节点是段落张量,下层中间节点是语句张量,每个叶子节点是词汇张量。
4. 问答匹配:
输入一个提问语句,Talk to Books 先把提问语句,翻译成一个定长的数值张量,然后在众多文章的张量森林中,寻找最贴切的词汇张量,也就是某棵树的叶子节点。如果不行,就寻找最贴切的语句张量,也就是某棵树的下层中间节点。如果不行,就寻找最贴切的段落张量,也就是某棵树的上层中间节点。如果还不行,就寻找最贴切的文章张量,也就是某棵树的根节点。[page]分页标题[/page]
难题在于,当文章数量很多,一棵树一棵树地逐个找一遍,计算量太大。所以需要一个办法,快速地从提问匹配到回答。
谷歌博文引荐了论文 [4],它用分类器,把提问匹配到数量固定的回答。分类器的办法,似乎不太可行,原因有二:
a.
当回答的数量非常庞大时,分类器势必非常复杂。
分类器越复杂,越需要的训练数据就越多。收集海量的训练数据,几乎是无法办到的事情。
b.
无论是书籍还是网文,数量每天都在快速增多。
分类类目数量增多,分类器的结构就必须随之改变,就必须重新训练分类器。
分类器似乎不可行,倒排索引是否可行呢?原理上似乎可行,但是占用的存储空间会非常庞大,因为倒排索引的 term,已经不再是每篇文章中出现的所有词汇了,而是,词汇张量 + 语句张量 + 段落张量 + 文章张量,组合爆炸的节奏。
5. 答案生成:
答案的生成,有两种方式,一个是摘要,如前所述。另外一个是把诸多段落语句,通过推理,串连在一起,更智能地生成答案。
譬如提问是 “孕妇是否能吃海鲜”,推理的办法是,先找到孕妇子宫中,羊水最重要的营养成分是什么。然后查找破坏羊水的营养成分,会有哪些物质。再然后检查海鲜中,是否富含这些破坏物质。
推理的办法,往往需要把跨段落,甚至跨文章的诸多语句,按逻辑顺序,串连在一起,组合成答案。看样子这次 Talk to Books,并没有涉及推理的难题。
总之,Talk to Books 的截图很震撼,但是两篇论文,似乎并没有满足我们所有的好奇心。
本文首发于微信公众号:新智元。文章内容属作者个人观点,不代表和讯网立场。投资者据此操作,风险请自担。

- AMD助力微软Windows 11 为用户带来强大、可靠的计算能力2021-10-09 16:20
- 游戏玩家为之疯狂!Chinajoy2021 AMD展台那些火爆的瞬间2021-08-02 15:39
- 全场最佳 AMD Chinajoy2021展台圆满收官2021-08-02 15:38
- AMD 锐龙5000G系列处理器正式亮相Chinajoy20212021-08-02 11:50
- 极速制胜 制霸游戏 AMD携多款游戏神器扬威Chinajoy2021-08-02 11:44
- 央视《新闻联播》头条聚焦铁建重工,聚力攻克“卡脖子”技术难题2021-03-22 11:08
- 刚刚!我又上央视新闻联播头条了!2021-03-22 11:04
- 中国电科(3月1日-3月7日)要闻回顾 | 资讯轻阅读2021-03-22 10:47
- 我国将建第一个国家公园:为何是三江源2021-03-22 10:43
- 美国硅谷上演“大逃亡”:郊区成科技精英避难所2021-03-22 10:41

- 18:09东方药林药业有限公司:秉持长期主义,稳步推进全球化市场布局
- 17:54广东康力医药:立足本土放眼全球,打造走向世界的中国健康名片
- 14:15从KS到CES Asia:纵深视觉科技全栈方案引爆光场显示市场
- 10:32康力医药:聚焦大众健康需求,打造一体化全链条服务生态
- 09:38华创农食相融,筑牢乡村粮食安全屏障
- 09:23东方药林小毛巾:天然竹琨选材,打造洗护好产品
- 14:52华创聚力创新,引领智慧人居新潮流
- 14:50康力医药:扎根行业三十载,书写民族健康品牌成长答卷
- 14:30东方药林:布局长远战略,绘就抗衰事业发展新图景
- 16:55东方药林:聚焦抗衰赛道,创新驱动企业高质量发展
- 10:27当行业需要“判断者”:张红梅以专业视角参与宠物科技领域重要评审工作
- 09:52华创政企携手,共建多元人居新生态
- 18:09华创践行担当,以初心赋能民生安居
- 18:03聚焦核心单品与场景创新:水井坊以消费者驱动破局存量时代
- 14:16华创精耕品质,打造宜居生活新标杆
- 20:38深耕供应链:从环境日看水井坊的绿色转型路径
- 20:38聚焦终端精细化运营,水井坊多维举措赋能渠道生态
- 14:41建筑工程专家王晗获聘元培工匠专家谷客座教授及高级智库专家
- 14:26清晨生物深耕文化保护,打造道养文化主题景区新地标
- 13:47中国氢储能产业加速落地: 邹昊参与推动新能源储能示范工程建设
- 15:22数智健康新机遇:大健康AI趋势与清晨生物HiLife平台新布局
- 15:05清晨生物全新品牌“清晨HiLife”——定义数智化健康发展新未来
- 14:47清晨Hilife健康伙伴“辰宝”上线啦! 不止是AI,更是懂你的智能助
- 14:27广州易萃享:数智赋能羊城家庭,打造全家健康守护首选品牌
- 09:14广州易萃享:扎根广州立足华南,树立区域精准营养行业标杆
- 08:59易萃享健康:数智技术打破壁垒,实现全民健康管理零门槛
- 09:29易萃享健康:全周期健康守护,打造家庭健康管理超级管家
- 17:36东方药林OMF2026全球抗衰领航者峰会举行,灵犀AI重磅发布
- 11:48易萃享:AI 科技深度赋能,让精准养生融入现代日常生活
- 10:45易萃享:千日匠心打磨,开创精准营养个性化全新赛道






